In the rapidly evolving field of synthetic biology, the integration of deep learning with protein design is revolutionizing how scientists approach enzyme engineering. For decades, researchers have sought to create enzymes with novel functions or enhanced activities, often relying on labor-intensive methods such as directed evolution or rational design. These approaches, while fruitful, are limited by the vast complexity of protein sequences and structures. Now, deep learning models are breaking through these barriers, enabling the generation of entirely new enzyme active sites with precision and efficiency previously unimaginable.
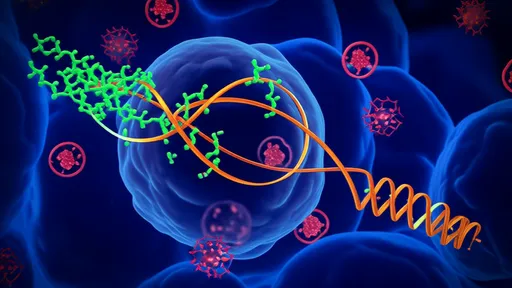
At the heart of this transformation are neural networks trained on massive datasets of protein sequences and three-dimensional structures. These models learn the intricate patterns and constraints that govern protein folding, stability, and function. By capturing the underlying principles of enzyme catalysis, they can propose mutations or entirely new sequences that are likely to form functional active sites. Unlike traditional methods, which often iterate through random mutations or rely on human intuition, deep learning can explore the protein sequence space more systematically and creatively, suggesting designs that might never occur to a human engineer.
One of the most promising applications is the de novo design of enzymes for non-natural reactions. Nature's enzymes have evolved over billions of years to perform specific biochemical tasks, but industrial and medical applications often require catalysts for reactions not found in biology. Deep learning models, such as generative adversarial networks (GANs) or variational autoencoders (VAEs), can be trained to generate protein sequences that fold into structures with customized active sites. These active sites are designed to bind transition states of desired reactions, effectively creating enzymes from scratch. Early successes include designed enzymes for Diels-Alder reactions, Kemp eliminases, and other abiotic transformations, demonstrating the potential to expand the toolkit of synthetic chemistry.
The process typically begins with defining the desired catalytic activity and identifying key residues or cofactors involved. Researchers then use deep learning to generate candidate sequences that meet these criteria. Advanced models incorporate physical constraints, such as energy minimization and structural stability, ensuring that the proposed proteins are not only functional but also fold correctly in vivo. This holistic approach reduces the risk of generating non-functional or unstable proteins, streamlining the experimental validation process. In several cases, computationally designed enzymes have shown significant activity when expressed in cells, validating the power of these AI-driven methods.
Another breakthrough is the ability to optimize existing enzymes for improved performance. Industrial enzymes used in biofuels, pharmaceuticals, or bioremediation often operate under non-physiological conditions, where natural enzymes may be inefficient or unstable. Deep learning can predict mutations that enhance stability, activity, or substrate specificity under these conditions. For instance, models trained on sequence-activity relationships can identify subtle changes that lead to higher turnover rates or broader substrate ranges. This capability is accelerating the development of biocatalysts for sustainable manufacturing, reducing reliance on harsh chemicals and energy-intensive processes.
Despite these advances, challenges remain. The accuracy of deep learning models depends heavily on the quality and diversity of training data. While databases like UniProt and the Protein Data Bank provide vast amounts of information, they are biased toward natural proteins, potentially limiting the exploration of novel sequence spaces. Additionally, predicting how generated sequences will behave in complex cellular environments is non-trivial; factors like solubility, expression levels, and post-translational modifications can affect outcomes. Researchers are addressing these issues by integrating multi-omics data and developing models that simulate in vivo conditions more accurately.
Ethical considerations also come into play, particularly as the line between natural and artificial biology blurs. The ability to design enzymes with unprecedented functions raises questions about safety and regulation, especially if these enzymes are used in open environments or in medical applications. Responsible innovation requires robust risk assessment frameworks and transparent reporting of methods and results. The scientific community is actively engaging with these issues, promoting guidelines that ensure the benefits of AI-driven protein design are realized without unintended consequences.
Looking ahead, the convergence of deep learning with other technologies like cryo-electron microscopy and high-throughput screening promises to further accelerate progress. As models become more sophisticated and datasets grow, we can expect to see enzymes designed for increasingly complex tasks, from carbon capture to targeted drug activation. This interdisciplinary effort is not only expanding our understanding of protein science but also opening new frontiers in biotechnology. The era of bespoke enzymes, tailored to meet specific human needs, is dawning, thanks to the transformative power of artificial intelligence.
In summary, deep learning is reshaping enzyme engineering by enabling the generation and optimization of active sites with remarkable precision. From de novo design to enhancing natural functions, these tools are unlocking possibilities that were once the realm of science fiction. As research continues to overcome current limitations, the impact on medicine, industry, and environmental sustainability will be profound, heralding a new chapter in the story of biological innovation.
By /Aug 27, 2025
By /Aug 27, 2025

By /Aug 27, 2025

By /Aug 27, 2025
By /Aug 27, 2025

By /Aug 27, 2025
By /Aug 27, 2025

By /Aug 27, 2025
By /Aug 27, 2025
By /Aug 27, 2025
By /Aug 27, 2025

By /Aug 27, 2025
By /Aug 27, 2025

By /Aug 27, 2025

By /Aug 27, 2025

By /Aug 27, 2025
By /Aug 27, 2025
By /Aug 27, 2025
By /Aug 27, 2025
By /Aug 27, 2025
